

{kind=link}

|
In the present day, we’re making out there a brand new functionality of AWS Glue Knowledge Catalog to permit computerized compaction of transactional tables within the Apache Iceberg format. This lets you maintain your transactional knowledge lake tables all the time performant.
Knowledge lakes have been initially designed primarily for storing huge quantities of uncooked, unstructured, or semi structured knowledge at a low price, and so they have been generally related to large knowledge and analytics use instances. Over time, the variety of potential use instances for knowledge lakes has advanced as organizations have acknowledged the potential to make use of knowledge lakes for extra than simply reporting, requiring the inclusion of transactional capabilities to make sure knowledge consistency.
Knowledge lakes additionally play a pivotal function in knowledge high quality, governance, and compliance, notably as knowledge lakes retailer growing volumes of vital enterprise knowledge, which frequently requires updates or deletion. Knowledge-driven organizations additionally have to maintain their again finish analytics programs in close to real-time sync with buyer purposes. This situation requires transactional capabilities in your knowledge lake to assist concurrent writes and reads with out knowledge integrity compromise. Lastly, knowledge lakes now function integration factors, necessitating transactions for protected and dependable knowledge motion between numerous sources.
To assist transactional semantics on knowledge lake tables, organizations adopted an open desk format (OTF), corresponding to Apache Iceberg. Adopting OTF codecs comes with its personal set of challenges: reworking present knowledge lake tables from Parquet or Avro codecs to an OTF format, managing numerous small information as every transaction generates a brand new file on Amazon Easy Storage Service (Amazon S3), or managing object and meta-data versioning at scale, simply to call just a few. Organizations are usually constructing and managing their very own knowledge pipelines to deal with these challenges, resulting in extra undifferentiated work on infrastructure. You might want to write code, deploy Spark clusters to run your code, scale the cluster, handle errors, and so forth.
When speaking with our clients, we discovered that essentially the most difficult side is the compaction of particular person small information produced by every transactional write on tables into just a few massive information. Massive information are sooner to learn and scan, making your analytics jobs and queries sooner to execute. Compaction optimizes the desk storage with larger-sized information. It modifications the storage for the desk from numerous small information to a small variety of bigger information. It reduces metadata overhead, lowers community spherical journeys to S3, and improves efficiency. While you use engines that cost for the compute, the efficiency enchancment can also be helpful to the price of utilization because the queries require much less compute capability to run.
However constructing customized pipelines to compact and optimize Iceberg tables is time-consuming and costly. You must handle the planning, provision infrastructure, and schedule and monitor the compaction jobs. For this reason we launch computerized compaction right this moment.
Let’s see the way it works
To point out you the right way to allow and monitor computerized compaction on Iceberg tables, I begin from the AWS Lake Formation web page or the AWS Glue web page of the AWS Administration Console. I’ve an present database with tables within the Iceberg format. I execute transactions on this desk over the course of a few days, and the desk begins to fragment into small information on the underlying S3 bucket.

I choose the desk on which I wish to allow compaction, after which I choose Allow compaction.
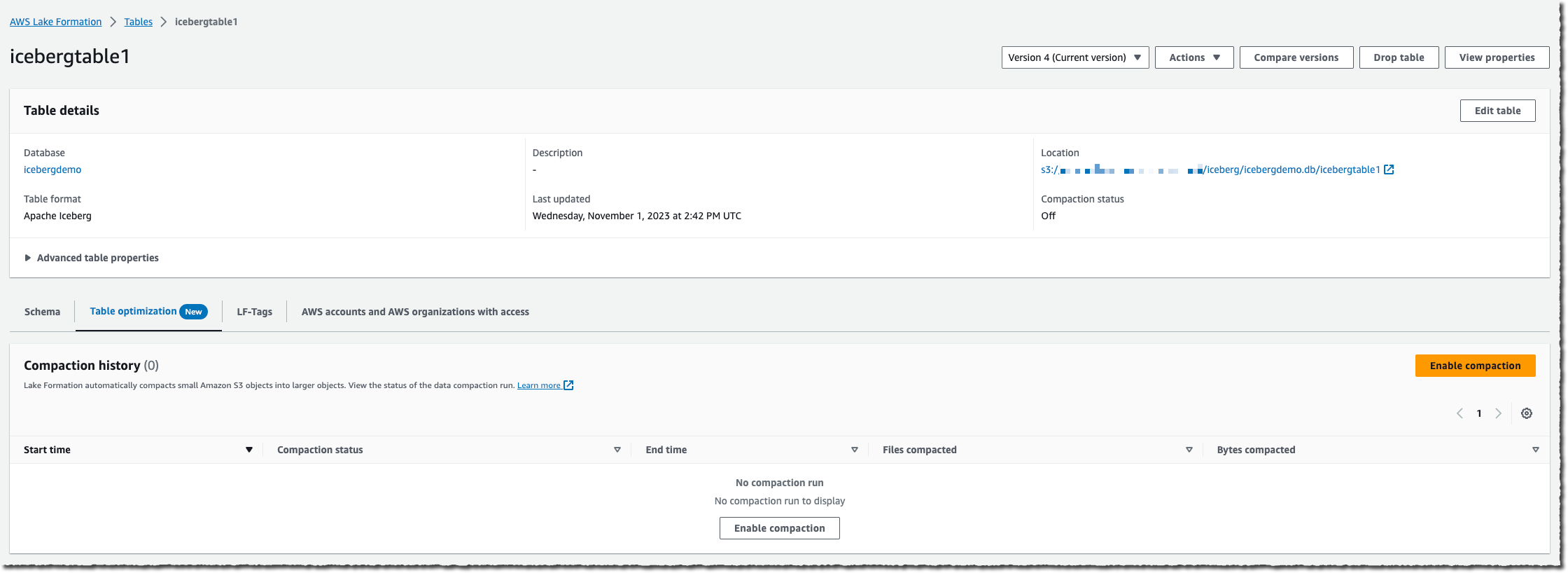
An IAM function is required to go permissions to the Lake Formation service to entry my AWS Glue tables, S3 buckets, and CloudWatch log streams. Both I select to create a brand new IAM function, or I choose an present one. Your present function should have lakeformation:GetDataAccess and glue:UpdateTable permissions on the desk. The function additionally wants logs:CreateLogGroup, logs:CreateLogStream, logs:PutLogEvents, to “arn:aws:logs:*:your_account_id:log-group:/aws-lakeformation-acceleration/compaction/logs:*“. The function trusted permission service title have to be set to glue.amazonaws.com.
Then, I choose Activate compaction. Et voilà! Compaction is computerized; there’s nothing to handle in your aspect.
The service begins to measure the desk’s price of change. As Iceberg tables can have a number of partitions, the service calculates this modification price for every partition and schedules managed jobs to compact the partitions the place this price of change breaches a threshold worth.
When the desk accumulates a excessive variety of modifications, it is possible for you to to view the Compaction historical past underneath the Optimization tab within the console.
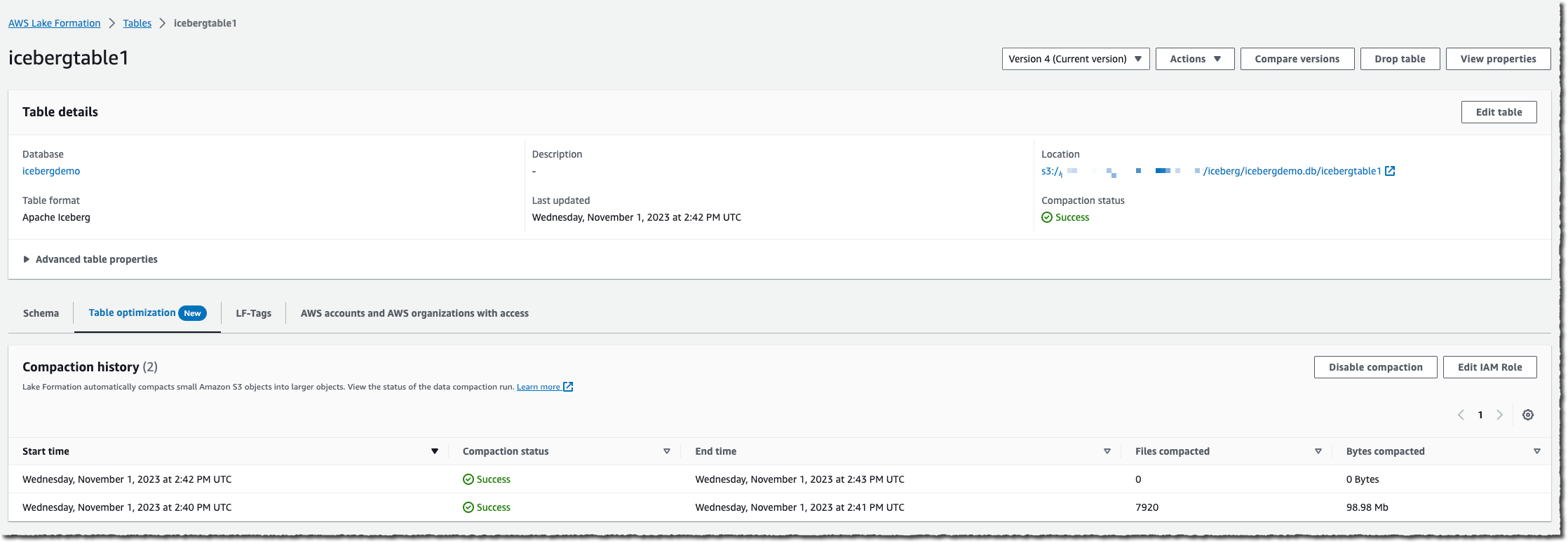
You too can monitor the entire course of both by observing the variety of information in your S3 bucket (use the NumberOfObjects metric) or one of many two new Lake Formation metrics: numberOfBytesCompacted or numberOfFilesCompacted.
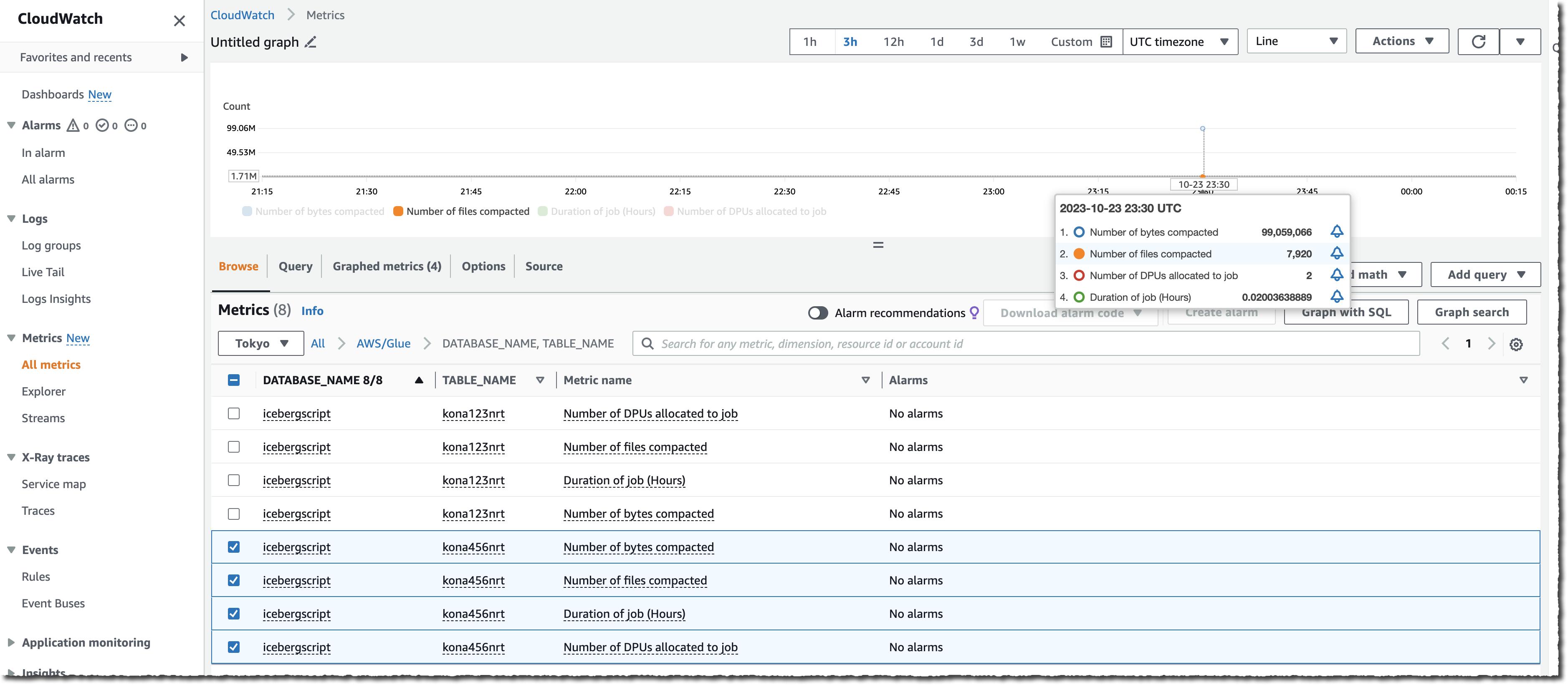
Along with the AWS console, there are six new APIs that expose this new functionality:CreateTableOptimizer, BatchGetTableOptimizer , UpdateTableOptimizer, DeleteTableOptimizer, GetTableOptimizer, and ListTableOptimizerRuns. These APIs can be found within the AWS SDKs and AWS Command Line Interface (AWS CLI). As standard, don’t overlook to replace the SDK or the CLI to their newest variations to get entry to those new APIs.
Issues to know
As we launched this new functionality right this moment, there are a few extra factors I’d prefer to share with you:
Availability
This new functionality is accessible beginning right this moment in all AWS Areas the place AWS Glue Knowledge Catalog is accessible.
The pricing metric is the information processing unit (DPU), a relative measure of processing energy that consists of 4 vCPUs of compute capability and 16 GB of reminiscence. There’s a cost per DPU/hours metered by second, with a minimal of 1 minute.
Now it’s time to decommission your present compaction knowledge pipeline and swap to this new, completely managed functionality right this moment.